Dataset description
We present a multi-modal indoor dataset for mobile robots, including synchronized RGB, depth, event streams, and IMU data. It addresses the challenges of event-based monocular depth estimation and other tasks in realistic indoor environments.

Figure 1 - Multi-Modal Indoor Dataset for Event-based Monocular Depth Estimation by Mobile Robots. Example of the dataset: RGB frames, Accumulative Polarity Events, BEHI, SAE, Tencode, EROS, and depth ground truth samples.
Dataset baselines
The Cycle Generative Adversarial Network (CycleGAN) is adapted to learn a bidirectional mapping between event-based representations H and monocular depth images Z. This approach uses two generators along with discriminators. The adversarial objective enforces realism in each target domain. Meanwhile, cycle-consistency and identity losses preserve geometric and structural information for robust depth estimation in indoor navigation scenarios.
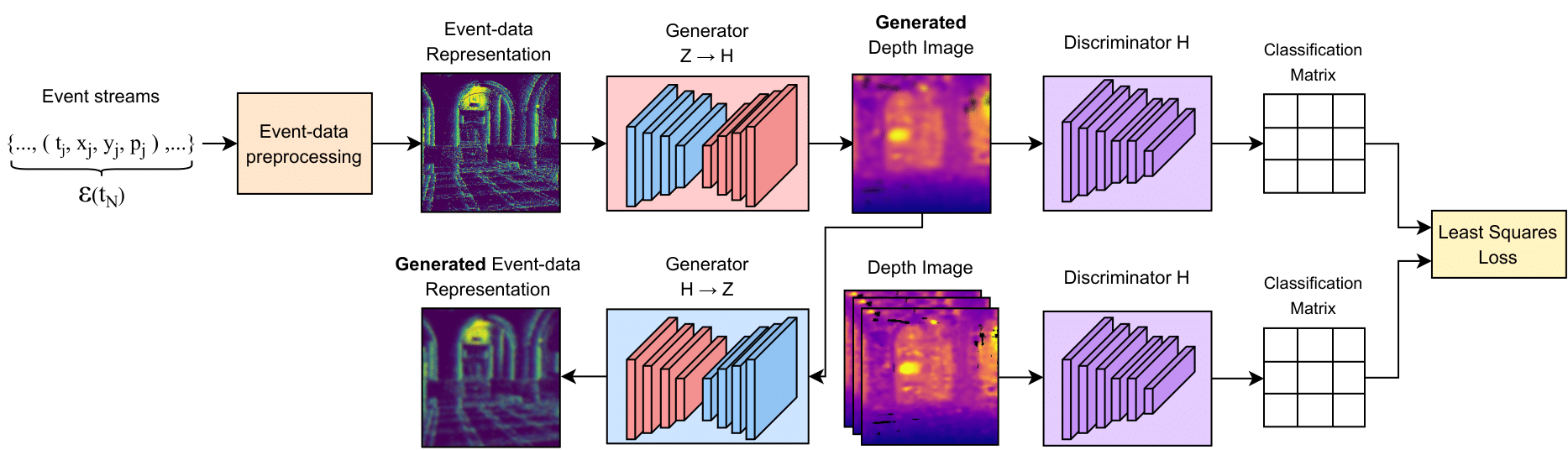
Figure 2 - Suggested CycleGAN architecture for event-based monocular depth estimation baseline. Event streams are preprocessed into dense representations, which are then translated into depth images and back through paired generators. Discriminators enforce realism in each domain using a least-squares loss, while cycle consistency enables reconstruction across event and depth domains.
The CycleGAN baseline was trained for 100 epochs with a batch size of 8 and the Adam optimizer. Table 1 summarizes the most relevant hyperparameters.
| Parameter | Value |
|---|---|
| Epochs | 100 |
| Batch size | 8 |
| Learning rate (G) | 2 × 10−4 |
| Learning rate (D) | 2 × 10−4 |
| β1 | 0.5 |
| β2 | 0.999 |
BibTeX
@misc{Bugueno2025MMIDEventDepth,
author="Bugueno-Cordova, Ignacio
and Luna, Gava
and Verschae, Rodrigo
and Ruiz-del-Solar, Javier
and Navarro-Guerrero, Nicolas",
title="Human-Robot Navigation using Event-based Cameras and Reinforcement Learning",
year="2025",
}